In our digital world, we’re surrounded by “smart” technology. Your email client flags junk mail, Netflix suggests movies you might love, and your phone’s digital assistant can understand your spoken commands. For decades, the pinnacle of programming was writing explicit, step-by-step instructions for a computer to follow. But how do you write “rules” for something as fluid and nuanced as human language or identifying a face in a crowd?
The simple answer is: you don’t. You let the machine figure it out for itself. This is the revolutionary idea at the heart of Machine Learning (ML). This field has moved from academic theory to the driving force behind some of the most transformative technology of our time.
Why a New Way of Thinking Was Necessary
Let’s start with a challenge. Your task is to write a computer program to recognize handwritten numbers from 0 to 9. Your first instinct, as a traditional programmer, might be to define a set of rules based on shapes. A ‘1’ is a vertical line. A ‘0′ is a closed loop. An 8’ is two loops stacked on top of each other.
You would then feed an image of a number to your program, which would check its pixels against your predefined rules. This seems logical, but it breaks down almost immediately when faced with the incredible diversity of human handwriting.

Is a ‘7’ with a line through the middle still a ‘7′? What about a ‘4′ with an open top? Or a ‘2’ with an elaborate loop at the bottom? Suddenly, your simple set of rules explodes into a hopelessly complex web of exceptions and conditions.
This problem isn’t unique to numbers. Let’s try differentiating animals. A simple rule could be: “If it has stripes, it’s a zebra.” But this rule is brittle. A tiger has stripes, yet it is not a zebra. You could refine the rule: “If it has
black and white stripes, it’s a zebra.” This works until you encounter an animal that breaks your rule again. We often don’t even know which features (like color, shape, or texture) are the right ones to focus on.
This is the fundamental limitation of explicit programming: we can’t possibly code for every eventuality in a complex world. We need a more robust approach. We need to let the machine learn from experience.
Defining “Learning” for a Machine
So, what does it mean for a machine to learn? The concept has been around for a while. In 1959, AI pioneer Arthur Samuel gave us the classic definition, describing Machine Learning as the field that provides computers with the “ability to learn without being explicitly programmed”. This captures the core departure from traditional methods.
However, a more formal and practical definition was proposed by Tom Mitchell in 1998, and it has become a cornerstone of the field:
“A computer program is said to learn from
experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.”
This might seem dense, but it’s a beautifully precise way to frame the learning process. Let’s break it down:
- Task (T): This is the “what.” It’s the specific job we want the machine to accomplish. For example, the task could be identifying spam emails, predicting house prices, or classifying a picture as containing a cat or a dog.
- Experience (E): This is the “how.” It’s the information we give the machine to learn from. Experience comes in the form of data. For our cat/dog task, the experience would be a massive dataset of thousands or even millions of images, each one providing an example.
- Performance ℗: This is the metric for success. How do we know if the machine is learning? We need to measure its performance. For the cat/dog classifier, our performance measure could be the percentage of new images it correctly identifies. If the accuracy goes from 60% to 95% after being trained on more data, we can say it has learned.
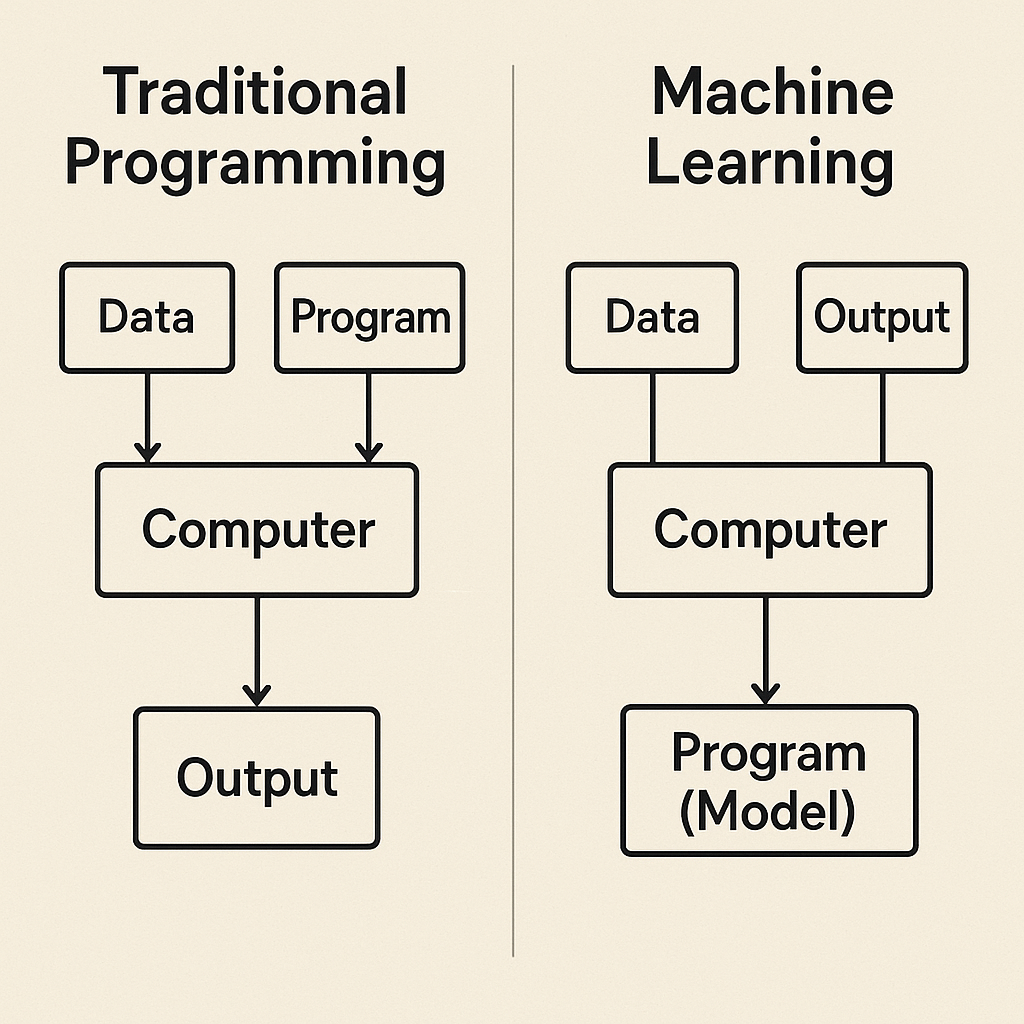
This framework marks a profound paradigm shift. In traditional programming, we feed
Data and a Program into a computer to get an Output. In Machine Learning, we feed
Data and the desired Output into a computer, and the computer generates the Program (Model) for us.
The Three Pillars of Machine Learning
Machine learning is not a monolith. It’s a diverse field with three primary paradigms, each suited to different problems and different types of data.
1. Supervised Learning: The Great Apprentice
Supervised learning is the most common and perhaps most intuitive type of ML. The core idea is that the machine learns from data that is
labeled. Think of the machine as an apprentice and the data as a series of lessons from a teacher, or “supervisor,” who provides the correct answers.
The “experience” given to the learner consists of both the data and its corresponding correct label. For instance, in a medical context, the data might be an MRI image, and the label could be “tumor” or “no tumor.”
Supervised learning is typically used for two main types of tasks:
- Classification: This is when the goal is to predict a discrete, categorical label. You are sorting inputs into distinct classes.
- Example: Identifying cat vs. dog images. The input is an image, and the output label is either “CAT” or “DOG”. The training data would be thousands of images that have already been correctly labeled by humans. The algorithm learns the visual patterns associated with each label.
- Regression: This is when the goal is to predict a continuous, numerical value. You aren’t sorting, you are estimating a quantity.
- Example: Predicting the price of a house. The input would be a set of features about the house (square footage, number of bedrooms, location), and the output label would be its exact price (e.g., $450,000). The algorithm learns the relationship between the house’s features and its final sale price.
2. Unsupervised Learning: The Data Detective
What happens when you have a mountain of data, but no labels? This is where unsupervised learning shines. Here, the machine is given a dataset and tasked with finding hidden patterns, structures, and relationships within it, all on its own. It’s less like an apprentice and more like a detective looking for clues without knowing what crime was committed.
The most common unsupervised learning task is
clustering. This involves grouping data points based on their similarities.
- Example: Imagine you are given thousands of images of two types of animals you’ve never seen before, all mixed. There are no labels to tell you what they are. By analyzing their features—shape, color, size, and ear shape—an unsupervised algorithm can automatically cluster them into two distinct groups. You might not know one group is “sloths” and the other is “caracals,” but you know they are different. This is incredibly powerful for market segmentation, genetic analysis, and social network analysis.
3. Reinforcement Learning: Learning by Doing
The final pillar is reinforcement learning (RL). This approach is quite different from the others. It’s about an
agent learning to behave in an environment by performing actions and seeing the results. There are no labeled datasets. Instead, the agent learns through trial and error, guided by a system of rewards and penalties.
Think about how a child learns to ride a bicycle.
- The agent is the child.
- The environment is the world, including the bicycle and the laws of physics.
- The actions are pedaling, steering, and braking.
- The feedback comes in the form of rewards and penalties. Successfully moving forward without falling is a positive reward. Tipping over is a negative penalty.
The ultimate goal of the agent is to learn a strategy, or “policy,” to choose actions that maximize its total cumulative reward over time. This powerful trial-and-error framework is what enables AIs to master complex games like Chess and Go, control robotic arms, and optimize the routes for self-driving cars.
A Glimpse Beyond the Pillars
While Supervised, Unsupervised, and Reinforcement Learning are the three main types, the field is vast and includes hybrid approaches. These include
Semi-supervised Learning (where you have a lot of data but only a few labels), Weakly-supervised Learning, and Self-supervised Learning, which are clever ways to create labels automatically from the data itself.
The Beginning of Your Journey
From recognizing your handwriting to discovering new medicines, machine learning is a revolutionary field built on a simple premise: that a machine can learn from data. By understanding the core concepts—the shift from explicit programming, the formal definition of learning through experience, and the three primary learning paradigms—you have taken your first, most important step into this exciting domain. The journey from here is one of constant discovery, where the only limit is the data we can gather and the questions we dare to ask.
Leave a Reply